|
1. Définition |
1. Définition Systčme d'exploitation :
- Application de gestion des ressources d'un ordinateur et de gestion de l'interaction entre ces ressources : Application ouverte aux développeurs pour que ceux-ci puissent créer leurs propres applications en utilisant les ressources proposées par le systčme d'exploitation. Certaines de ces applications peuvent ętre des applications "systčmes" destinées ŕ ętre utilisées en association rapprochée avec le systčme d'exploitation, exemple : Gestionnaire d'environnement fenętré. A ce titre, ces applications pourraient ętre assimilées au systčme d'exploitation. Conception en couches : Systčme d'exploitation généralement développé sous la forme d'un noyau (kernel) comportant l'ensemble des fonctionnalités de base de gestion des ressources, accompagné d'un ensemble d'utilitaires indépendants ou interdépendants apportant des services plus élaborés que les fonctionnalités de base du noyau. 2. Historique
Apparus avec les premiers ordinateurs dans les années 50. Traitement par lots (années 50)
Le systčme d'exploitation exécute séquentiellement des lots de programmes : des batchs.
00000000111111111122233333444444444444555566666666 Pas d'interaction temps réel entre un programme et son utilisateur. Multiprogrammation (années 60) L'accčs aux ressources étant fréquement lent, l'introduction de la multiprogrammation a permis l'optimisation de leur utilisation. Les programmes ne sont plus exécutés les uns aprčs les autres, mais "en męme temps". Lorsqu'un programme en exécution accčde ŕ une ressource (voire quand il le souhaite męme sans accéder ŕ une ressource), il peut rendre la main au systčme d'exploitation de façon ŕ ce que celui-ci puisse donner la main ŕ un autre programme. Il récupérera la main lorsque le systčme d'exploitation la lui redonnera.
00111111111234555666666660000122334450033444444444 Problčme : Rien n'oblige un programme ŕ rendre la main. Il peut donc accaparer le processeur. Avec l'apparition début 60 du couple clavier-écran connectable aux ordinateurs, l'interaction temps réel entre un programme et son utilisateur devient possible. Temps partagé (années 70)
Le systčme d'exploitation devient maître de l'allocation des temps de calcul. Il les attribue de façon discrétionnaire en tenant éventuellement
compte de priorités. Chaque programme a l'impression d'ętre le seul programme en exécution sur l'ordinateur.
01234560123456012345601345601346014601460146141444
Un programme ne peut pas accaparer le processeur. Unix
Créé au tout début des années 70 aux Bell Labs, composante d'AT&T, par une équipe dirigée par Kenneth Thompson. Linux
Ersatz d'Unix (męmes commandes, code différent) créé par Linus Torvald au début des années 90. Inspiré d'Unix System V. Principales distributions : Debian, Ubuntu (issue de Debian), Mint (issue de Ubuntu) , Red Hat, Fedora (supportée par Red Hat), OpenSUSE, ... MS/DOS, Windows, Windows NT et Windows Server Ligne des systčmes d'exploitation de Microsoft Corp..
MS/DOS : Systčme d'exploitation fourni au début des années 80 par Microsoft ŕ IBM pour le nouvel ordinateur personnel IBM PC. Systčme d'exploitation
racheté par Microsoft ŕ la société SCP. Windows 1.0 ŕ Windows 3.11 (1985 ŕ 1993) : Interface graphique produite par Microsoft pour le systčme d'exploitation MS/DOS. Apport du réseau avec Windows 3.11 pour workgroup.
Windows 95 ŕ Windows Millenium (1995 ŕ 2000) : Transformation de Windows en un systčme d'exploitation classique, c'est ŕ dire muni d'un
noyau propre.
Windows NT 3.51 et Windows NT 4.0 (1993) : Systčme d'exploitation ŕ vocation professionnelle caractérisé par un noyau entičrement réécrit
par rapport au noyau de Windows 95 dans le but pour Microsoft de fusionner in fine les noyaux de ses systčmes d'exploitation personnels et professionnels. Windows XP ŕ Windows 10 (2001 ŕ 2020) : Versions poste client ŕ vocation personnelle ou professionnelle. Windows Server 2000 ŕ Windows Server 2019 (2000 ŕ 2020) : Version serveur professionnelle. Mac OS et Mac OS X Ligne des systčmes d'exploitation d'Apple pour ses Macintosh.
Apparu en 1984 pour l'ordinateur Apple Macintosh. Google Android, Apple iOS
Systčmes d'exploitation pour téléphone portable de toutes marques pour Android, de marque Apple pour iOS. 3.1. Multi-processus
Exécution concurrente possible de plusieurs processus indépendants. 3.2. Multi-utilisateurs
Gestion de plusieurs utilisateurs regroupables en groupes d'utilisateurs.
Utilisation des utilisateurs et des groupes d'utilisateurs pour attribuer des autorisations (des permissions) sur tout ou partie des ressources. Existence d'un utilisateur particulier, l'administrateur, qui peut tout faire, y compris se donner tout privilčge ou toute autorisation dont il ne dispose a priori pas. Son nom est root sous Unix et administrateur sous Windows pour les releases françaises (administrator en anglais). 3.3. Multi-tâches Plusieurs processus en fonctionnement s'exécutent en parallélisme simulé (voir ci-dessus). 3.4. Multi-sessions
Plusieurs utilisateurs peuvent ouvrir simultanément une session de travail et travailler en męme temps. Ces sessions peuvent ętre locales ou ŕ distance
(via réseau), en ligne de commandes ou en interface graphique suivant les composants logiciels utilisés. Composants caractérisés par l'existence
d'une partie serveur (un service) et d'un logiciel client. L'interopérabilité est possible entre systčmes d'exploitation différents. Tout est une question de composant serveur et de logiciel client. 3.5. Multi-threads Thread (processus léger) : Fil d'exécution parallčle amorcable au sein d'un processus (ou d'un autre thread).
Intéręt des threads lancés par un processus ou un thread : Ils sont exécutés dans la męme zone mémoire que le processus ou le thread qui leur
a donné naissance et ont un accčs complet ŕ cette zone mémoire. Ils ne nécessitent donc pas de dispositifs de développement complexe pour ętre utilisés.
De plus, cette absence de contrôle entraine une grande rapidité. 3.6. Multi-processeurs
Les systčmes d'exploitation ont la possibilité d'exploiter plusieurs processeurs quand il en existe plusieurs dans l'ordinateur. Deux concepts historiques plus complémentaires qu'antagonistes : Les ordinateurs ŕ mémoire distribuée et les ordinateurs ŕ mémoire partagée. Mémoire distribuée
La machine est construite avec n processeurs disposant chacun de leur mémoire propre. Les communications entre processus se font par l'intermédiaire
de messages avec intervention des processeurs sur lesquels les processus sont en exécution. Mémoire partagée
La machine est construite avec n processeurs partageant une zone de mémoire unique. Les communications peuvent ętre réalisées par simple écriture
mémoire si on utilise la programmation multi-threadée. 3.7. 32 bits, 64 bits Les processeurs manipulent des mots de données. Ces mots ont une largeur définie par l'architecture du processeur. Cette largeur a évolué au cours du temps : 8 bits dans les années 70, 16 bits au début des années 80, 32 bits des années 80 au début des années 2000, 64 bits depuis le début des années 2000.
Historique (trčs) partiel des processeurs Intel
Historique (trčs trčs) partiel des processeurs AMD
Cette largeur est l'un des paramčtres de quantification de la puissance d'un ordinateur : plus large = plus puissant. Un mot plus large
permet de manipuler des nombres plus grands en un męme nombre de cycles d'horloge -> plus de précision en moins de cycles. Un mot plus large
permet d'adresser plus de mémoire car ces mots sont utilisés pour définir les adresses mémoire et les quantités de mémoire -> possibilité
de gérer plus de mémoire sans dispositif complexe et lent (pagination) pour adresser cette mémoire :
Le choix entre générer une application 32 bits et générer une application 64 bits est réalisé au moment de la compilation et de l'édition de
liens. Au prix du respect de quelques précautions de développement, en particulier pour tout ce qui relčve des manipulations explicites de pointeurs
et des allocations dynamiques de mémoire, changer de cible de compilation et d'édition de lien ne pose pas de problčme. 3.8. Sécurisé
Les systčmes d'exploitation ont été progressivement munis d'un ensemble de caractéristiques permettant de gérer la sécurité : 3.8.1. Audit, journalisation Les activités du systčme d'exploitation et surtout les incidents associés ŕ ces activités sont enregistrées.
Les activités des utilisateurs peuvent ętre enregistrées : Existence de journaux permettant de lister les événements audités enregistrés. 3.8.2 Chiffrement
Les informations sont stockées/transférées sous une forme non directement lisible. Par extension le chiffrement permet l'authentification de
l'origine des données (la signature), la vérification de l'intégrité des données, ... Chiffrement symétrique
Le chiffrement est dit symétrique lorsque la męme clé est utilisée pour chiffrer et déchiffrer. Chiffrement asymétrique
Le chiffrement est dit asymétrique lorsque deux clés différentes sont utilisées pour le chiffrement et le déchiffrement d'un message.
Une premičre clé appelée publique servira pour le chiffrement. Elle est créée est transmise par le destinataire du message ŕ l'émetteur
du message chiffré qui s'en sert pour chiffrer son message. Une seconde clé appelée privée est elle aussi créée par le destinataire
du message. Elle servira pour le déchiffrement. Cette clé est bien entendu non déduisible de la clé publique. La clé privée est destinée ŕ l'usage
exclusif du destinataire et n'est donc transmise ŕ personne.
Les réseaux d'informations sont vieux comme le monde :
Les concepts fondateurs de ce que les réseaux de données modernes allaient devenir ont été posés dans les années 1950 :
Naissance en 1969 du réseau ARPANET basé sur ces concepts. Naissance du protocole TCP/IP au début des année 1970 (publication officielle en 1973). Adoption de TCP/IP par ARPANET en 1983 car le protocole NCP interdisait l'interopérabilité avec d'autres réseaux que ceux basés sur le męme matériel que celui d'ARPANET.
Il est impossible de définir de façon univoque la naissance d'Internet car Internet est un réseau d'interconnexion de réseaux. ARPANET en
est l'une des premičres pierres au milieu des années 80. Le déploiement mondial d'Internet a été initié au tournant des années 80-90. L'Université
de Franche-Comté est connectée au réseau Internet depuis 1992 initialement par un lien ŕ 256 Kbits/s. 4.1. Communication entre machines par l'intermédiaire d'un réseau Toute machine physiquement connectée ŕ un réseau peut "théoriquement" communiquer avec toute autre machine elle-même physiquement connectée ŕ ce męme réseau. Dans la pratique, c'est loin d'être systématiquement le cas à cause de limitations techniques souhaitées ou non.
Un message envoyé d'une machine à une autre machine est segmenté en un ensemble de morceaux appelés paquets. Chacun de
ces paquets est marqué par la machine source avec, entre autres informations de signalisation, son nom et le nom de la machine cible et est
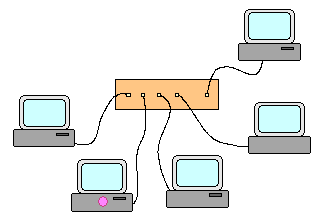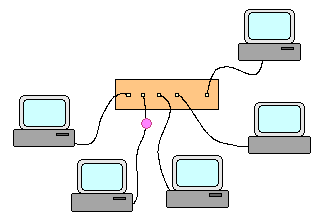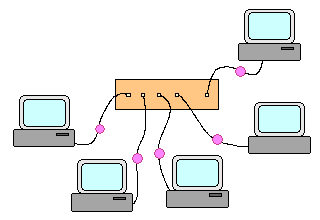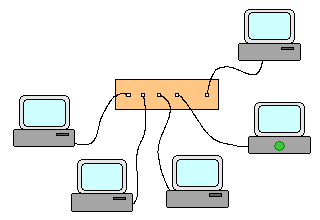
émis sur le réseau à destination de cette machine. Le transfert de ces paquets requière la présence d'une infrastructure matérielle gérée au moyen d'une infrastructure logicielle. 4.1.1. Infrastructure matérielle Réseau physique : Un réseau physique est constitué d'un ensemble de liens de communication interconnectant les machines et est caractérisé par le fait que chaque machine peut communiquer "directement" avec toute autre machine du même réseau physique c'est ŕ dire qu'il existe un chemin (unique ou non) entre les machines de chaque couple de machines connectées au réseau. Dans le cas des réseaux ethernet sur double paires torsadées (technologie filaire la plus courante actuellement), les machines sont interconnectées via des concentrateurs (hubs) ou des commutateurs (switchs).
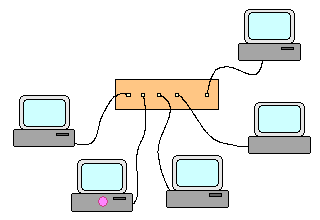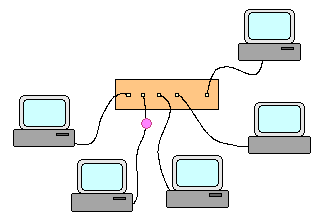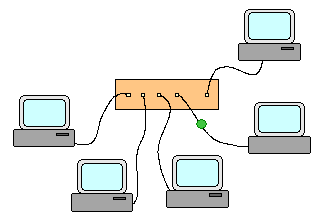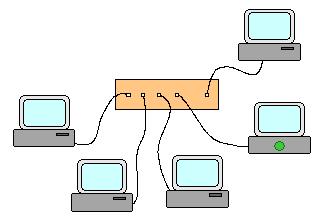
Concentrateur (hub) : Un concentrateur relie les machines en étoile. Il duplique et transmet tout paquet à toutes
les machines qui lui sont directement connectées. Une machine cible conservera et exploitera les paquets qui lui sont destinés et oubliera
les autres.
Trajet des paquets en cas d'utilisation d'un concentrateur Les réseaux sans fil fonctionnent en mode concentrateur. Par nature les réseaux ŕ base de concentrateurs sont insécurisés car toutes les machines reçoivent toutes les informations. Ils sont donc fréquement chiffrés, mais cela ne change pas la nature du problčme.
Commutateur (switch) : Un commutateur relie les machines en étoile et transmet un paquet ŕ la seule machine ŕ laquelle il est
destiné -> Une machine reçoit les seuls paquets qui lui sont destinés.
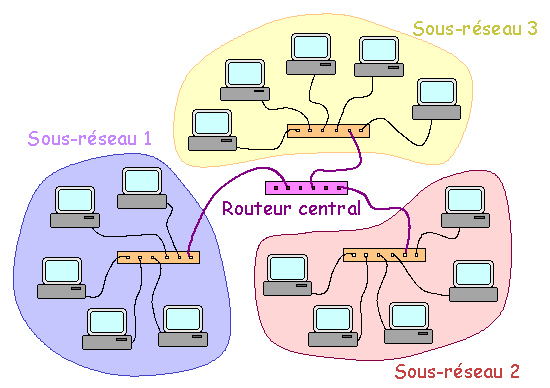
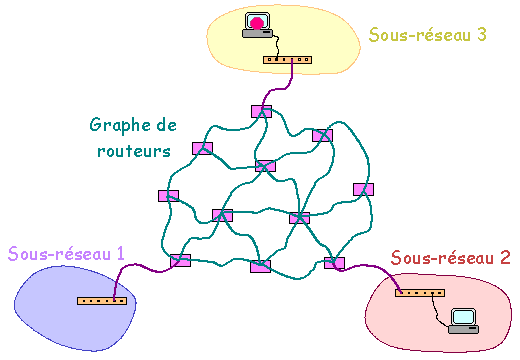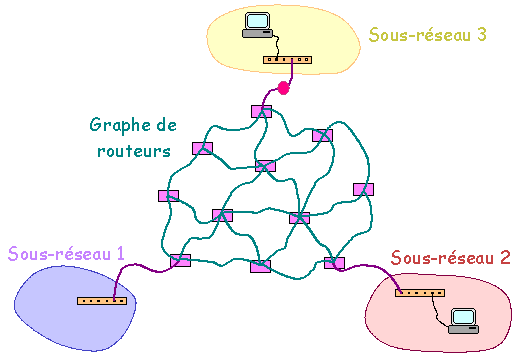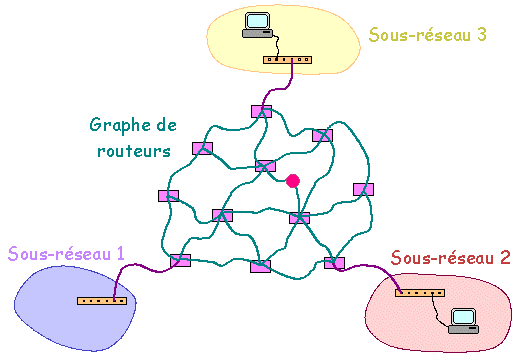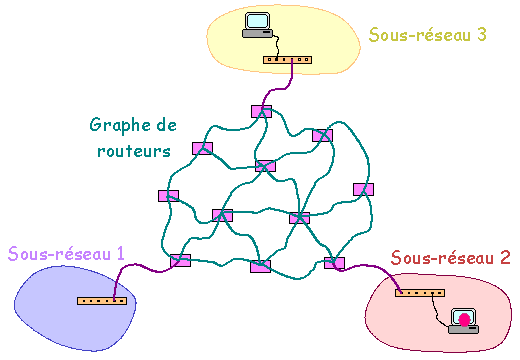
Trajet des paquets en cas d'utilisation d'un commutateur Un réseau peut être constitué par une étoile (éventuellement une étoile à plusieurs niveaux) de commutateurs ou concentrateurs sur lesquels viennent se connecter en étoile les machines. Quoi qu'il en soit, il ne doit exister qu'un seul chemin entre tout couple de machines. Interconnexion de réseaux et routage : Deux ou plusieurs réseaux physiques séparés peuvent être connectés entre eux via un routeur. Un tel matériel est capable de "router" les paquets entre les réseaux qui contiennent respectivement les machines source et cible. Dans les cas simples, les réseaux sont directement connectés sur un routeur unique qui après configuration semble agir comme un commutateur.
Construction d'un réseau global Dans les cas plus complexes (réseaux d'entreprise, Internet), un seul routeur ne permet pas l'inter-connexion de l'ensemble des réseaux. Plusieurs routeurs reliés entre eux consécutivement sont alors utilisés sur le chemin des paquets.
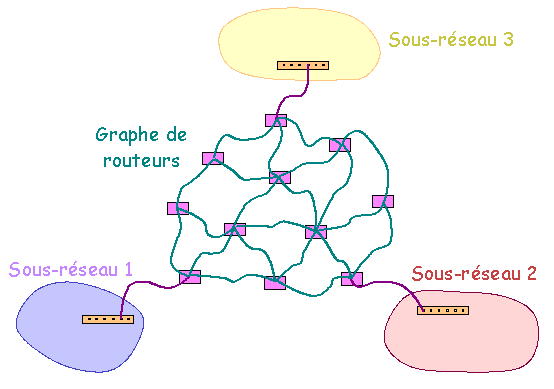
Construction d'un réseau global Pour des raisons de pérennité de fonctionnement et capacité de transfert d'information, le réseau de routeurs, au lieu d'être construit en étoile, pourra être construit en graphe (voir ci-dessus). Plusieurs chemins pourront exister pour relier un réseau et un autre réseau. Pour un même message, les paquets peuvent transiter par des chemins différents et même arriver dans un ordre différent de celui de départ. Le matériel actif du réseau se contente d'assurer le transfert de l'information. Ce sont les machines cibles qui reconstituent la cohérence des messages à l'arrivée.
Construction d'un réseau global Les routeurs ont une "connaissance" (statique ou dynamique) de la topographie globale du réseau permettant ainsi de résoudre le problème du choix et de l'optimisation des liens de transit. D'un point de vue physique, la différence entre routeur et commutateur-concentrateur est la capacité ŕ relier les routeurs en graphe alors qu'avec les commutateurs et les concentrateurs la liaison doit ętre rélaisée en étoile. On verra plus loin que les routeurs ont aussi un rôle "logique". Remarque : Tel que présenté ci-dessus, l'ensemble des machines reliées en étoile par une suite de concentrateurs ou de commutateurs peut être interprété comme constituant un réseau unique. Dans la pratique, l'infrastructure logicielle (voir ci-dessous) qui est greffée sur l'infrastructure matérielle permet de constituer des "sous-réseaux logiques" moins étendus. Il est ainsi possible de gérer 2 (ou plusieurs) sous-réseaux logiques indépendants en utilisant un seul concentratreur ou commutateur. S'il est souhaité d'interconnecter ces sous-réseaux, il faudra en plus faire appel à un appareil (routeur ou ordinateur assurant une fonction de routage) assurant le routage. 4.1.2. Infrastructure logicielle L'infrastructure logicielle d'un réseau informatique est basée sur l'utilisation de un ou plusieurs protocoles de communication (i.e. langage de communication d'informations entre ordinateurs). Les protocoles les plus courants ont été TCP/IP, NetBEUI et IPX/SPX. TCP/IP est le protocole de l'Internet et s'est généralisé. Une différence la plus marquante existant entre ces trois protocoles tient ŕ la routabilité. En effet, TCP/IP est assez facilement "routable" (et bien entendu est géré par les routeurs) et permet donc d'interconnecter des sous-réseaux. NetBEUI ne l'est pas. IPX/SPX l'est moins facilement que TCP/IP. Cette caractéristique ainsi que sa relative simplicité et sa capacité ŕ supporter des réseaux de tailles importantes explique l'adoption de TCP/IP pour le réseau Internet.
L'infrastructure logicielle comprend pour chaque protocole : 4.2. TCP/IP TCP/IP : Transfert Control Protocol / Internet Protocol TCP/IP intègre, outre des paramètres permettant de nommer les machines et de les placer dans des sous-réseaux, un ensemble de paramètres destinés au routage.
TCP/IP existe en version 4 (TCP/IPv4) et en version 6 (TCP/IPv6). 4.3. TCP/IPv4 4.3.1. Paramètres TCP/IP généraux
- Adresse IP : Une machine est nommée de manière unique sur son réseau physique par son "adresse
IP" formée de 4 nombres entiers compris entre 0 et 255 (nombres entiers non signés définis sur 8 bits).
- Masque de sous-réseau (Subnet Mask) : Formé de 4 nombres entiers compris entre 0 et 255, le masque de
sous-réseau permet d'indiquer à une machine quelles sont les adresses IP des machines qu'elle devra considérer comme faisant partie
de son sous-réseau logique (i.e. les machines avec lesquelles elle peut communiquer sans routage). Il est bien entendu nécessaire que toutes
les machines d'un sous-réseau aient le męme masque de sous-réseau pour que chacune d'entre elles puisse avoir des communications bidirectionnelles
avec chacune des autres machines.
Les masques de sous-réseau ne sont pas considérés arbitrairement. Ils sont construits de gauche à droite au moyen d'une
suite de bits à 1 complétée d'une suite de bits à 0. Définition des différentes classes IP - Passerelle par défaut (Gateway) : Il s'agit de l'adresse IP vers laquelle seront envoyés tous les paquets non destinés à une machine du même sous-réseau que la machine source. Un routeur ou un ordinateur assurant le routage sera installé à cette adresse pour les réceptionner et assurer la transmission (routage) vers le sous-réseau destination. C'est dans cette fonctionnalité de transfert que se trouve le rôle "logique" des routeurs pour le protocole TCP/IP. 4.3.2. Paramètres de configuration DNS La technique de dénomination par adresse IP (une série de 4 nombres entiers non signés définis sur 8 bits) est pratique pour les ordinateurs car facilement manipulée par eux en raison de l'utilisation d'une formulation ŕ base de nombres entiers non signés. En revanche, la mémorisation est difficile pour les individus qui ont plus de facilités ŕ manipuler des informations alphabétiques ou alphanumériques que numériques. Développement d'une convention de dénomination supplémentaire permettant de désigner chaque machine par un ou plusieurs noms IP alphanumériques. Lorsqu'un tel nom est utilisé, une résolution directe est réalisée ayant pour but de déterminer l'adresse IP correspondante qui est utilisée de façon transparente ŕ la place du nom IP. Moins utile, car généralement utilisée de façon explicite, l'opération inverse appelée résolution inversée existe aussi permettant de déterminer le ou les nom IP définis pour une adresse IP.
Principe : Une machine porte un nom et appartient ŕ un domaine TCP/IP qui peut lui-męme ętre le sous-domaine d'un autre domaine
TCP/IP, etc. L'ensemble forme ce que l'on appelle le nom IP.
Les parties alphanumériques du nom IP sont délimitées par des points avec, de gauche à droite, le nom de la machine,
puis les différentes parties du nom de domaine du plus particulier au plus général. Exemple : 172.20.128.99 <=> bunny.edu-info.univ-fcomte.fr est la machine bunny du sous-domaine edu-info.univ-fcomte.fr du sous-domaine univ-fcomte.fr du domaine fr.
Les listes de couples (adresse IP, nom IP) qui permettent cette double dénomination peuvent être gérées de deux manières :
Les serveurs DNS sont généralement implantés et configurés sous une forme arborescente calquée sur l'arborescence des domaines
TCP/IP qu'ils représentent. Chaque serveur gérera les noms de machine associés au nom de domaine dont il est le nœud.
Un serveur DNS réalise les tâches suivantes :
Il existe 3 paramčtres principaux relatifs ŕ la configuration DNS d'une machine cliente sous le protocole TCP/IP : 4.3.3. DHCP Tous les paramčtres nécessaires ŕ la configuration de l'infrastructure TCP/IP d'un parc de machines clientes pourront ętre renseignés soit directement sur chaque ordinateur, soit sur un serveur DHCP (Dynamic Host Configuration Protocol) qui sera contacté par l'intermédiaire du réseau par chaque machine cliente au moment de son démarrage.
L'intérêt de l'utilisation de DHCP réside dans les points suivants : On constate une convergence entre DNS et DHCP (et WINS, non décrit ici) permettant, via des bases de données spécifiques ŕ chaque service mais synchronisées, d'assurer la cohérence des informations transmises aux postes clients pour leur permettre de gérer la problématique de la configuration réseau et de la détermination des noms des machines (les leurs et ceux des autres machines). 4.3.4. Filtrage IP
Le protocole TCP/IP permet généralement l'implantation de fonctions de filtrage tant du point de vue des paquets sortants que du point
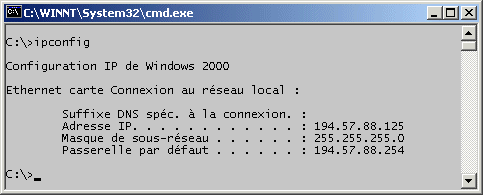
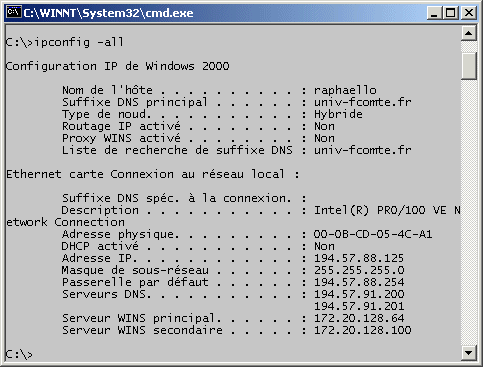
de vue des paquets entrants. 4.3.5. Commandes clavier historiques liées à TCP/IP TCP/IP est généralement associé ŕ un certain nombre de commandes clavier permettant de vérifier/modifier sa configuration, de diagnostiquer son bon fonctionnement ainsi que la capacité de l'ordinateur ŕ joindre d'autres machines sur le réseau. ifconfig, ipconfig
La commande Unix ifconfig permet de visualiser la configuration TCP/IP des différentes interfaces (cartes) réseau présentes
dans la machine. La commande ifconfig est dépréciée dans les distributions Linux récentes. Elle est remplacée par la commande ip. L'équivalent de ifconfig est ip addr. Sous Windows, le nom de cette commande est ipconfig.
ipconfig
ipconfig -all
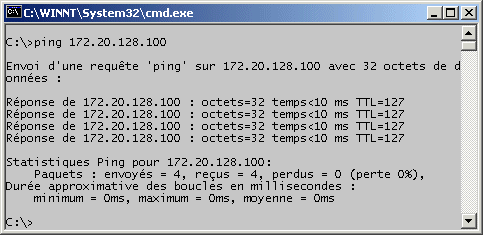
La commande ping permet de tester la présence d'une machine sur le réseau.
ping
Attention : Pour des raisons de sécurité, il est possible qu'une machine en fonctionnement ne réponde pas ŕ la commande ping. Les firewalls bloquent
fréquement les ping. Les routeurs bloquent fréquement les ping.
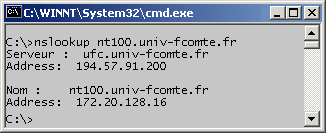
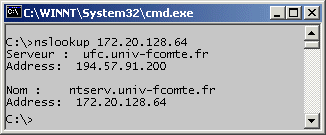
La commande nslookup permet d'interroger son serveur DNS pour obtenir les adresses IP correspondant à un nom IP (résolution directe),
ou les noms IP correspondant à une adresse IP (résolution inverse).
nslookup traceroute, tracert
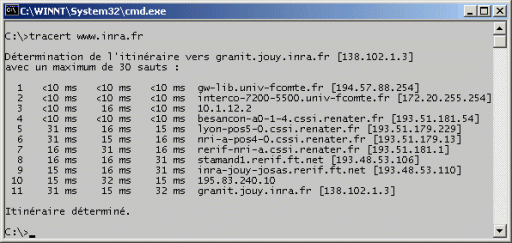
La commande traceroute permet d'obtenir la liste des matériels réseau (routeurs) traversés pour joindre une autre machine. Sous Windows, le nom de cette commande est tracert.
tracert 4.3. Les autres protocoles TCP/IP est devenu le protocole standard. Il en a toutefois existé d'autres. - IPX/SPX : Protocole développé par Novell pour la gestion de réseaux locaux de PC sous MS/DOS puis Windows. Abandonné en 1998. - NetBEUI : Protocole développé par IBM. Adopté par Microsoft ŕ la fin des années 1980 pour la gestion de réseaux locaux dans les premičres versions de Windows en association avec NetBIOS. Existence encore actuellement de caractéristiques dans Windows directement héritées de NetBIOS. Exemple : Nom de machine sous forme alphanumérique sur 15 caractčres affichés en majuscule. - Appletalk : Protocole historique d'Apple. Apparu en 1984, abandonné progressivement dans les années 90, définitivement juste aprčs l'an 2000. - Token ring : Protocole d'origine IBM. Apparu au mileu des années 1980. - ATM : Développé au milieu des années 90 comme solution pour la création de réseaux interopérant de la data et de la voix. Support de la qualité de service (QoS). N'a jamais su dépasser les réseaux WAN (Wide Area Network) spécialisés pour aller aux réseaux LAN (Local Area Network). 5. Unix et Linux 5.1. Généralités
Unix, męme s'il est maintenant trčs fréquemment (mais pas systématiquement) accompagné d'un environnement de travail graphique fenętré avec
utilisation de la souris, a été conçu ŕ une époque oů ce type d'environnement n'existait pas. Il était alors administré en ligne de commande
et par modification directe de fichiers de configuration (généralement au format texte) au moyen d'un éditeur. Unix interprčte les commandes saisies au clavier au moyen d'un interpréteur de commande associé ŕ un shell d'exécution. Les shells sont aussi des langages de développement et permettent de créer des fichiers exécutables composés de commandes. Ce type de fichier est utilisé par exemple pour réaliser l'installation de programmes. Il existe différents shells : sh, csh, ksh, bash, ... 5.2. 32 bits ou 64 bits
Linux est généralement disponible en 32 bits et en 64 bits. 5.3. Systčme de fichiers
Support natif des systčmes de fichiers (tailles ci-dessous dépendantes des architectures matérielles et en particulier des largeurs de mot des processeurs)
:
Systčme de fichiers du systčme d'exploitation monté ŕ la racine / qui peut contenir des fichiers et des répertoires, répertoires qui peuvent
eux-męmes contenir des fichiers et des répertoires, ... 5.4. Topographie
- / : Racine du systčme d'exploitation. 5.5. Configuration, paramétrage
L'essentiel des fichiers de configuration du systčme d'exploitation se trouve sous /etc. 6.1. Généralités
L'administration Windows Server est généralement réalisée au moyen des utilitaires graphiques disponibles au sein du systčme d'exploitation.
Ces utilitaires sont trouvés dans les Outils d'administration disponibles dans le Panneau de configuration. Un outils d'administration supplémentaire nommé Gestionnaire de serveurs est ajouté aux machines exécutant un systčme d'exploitation Windows Server. Il est configuré pour ętre lancé automatiquement ŕ l'ouverture de session de l'administrateur. Il permet de réaliser l'administration des services qui sont généralement mis en exploitation sur ce type de machine, services qui justifient l'installation d'une machine Windows Server et non d'une machine Windows cliente simple qui n'en dispose d'ailleurs généralement pas.
L'administration en ligne de commande est possible. Windows Server propose deux interpréteurs de commandes : Windows Server peut ętre installé sans interface utilisateur graphique. L'administration est réalisée en ligne de commande. 6.2. 32 bits ou 64 bits
Windows Server n'est plus distribué qu'en 64 bits depuis la version 2012 (depuis la version 2008 R2 pour ętre exact qui est une release de
Windows 2008). Toutes les versions de Windows, Server ou non, sont munies d'un émulateur permettant d'exécuter les applications compilées
en 32 bits. Différentes possibilités sont offertes pour repčrer les applications 32 bits : 6.3. Systčme de fichiers
Support natif des systčmes de fichiers :
Organisation des volumes en unités désignées par une lettre majuscule de l'alphabet. Systčme d'exploitation généralement situé sur l'unité
C:. Répertoire racine d'une unité de lettre X : X:\.
Lettres d'unité utilisables mais non proposées directement : A et B. Ces lettres étaient historiquement utilisées pour les disquettes, les disques
zip, ... 6.4. Topographie
Répertoire racine de l'unité contenant le systčme d'exploitation : C:\ 6.5. Workgroups et domaines
Il existe deux possibilités d'intégration d'un poste client sous Windows au sein d'un groupe d'ordinateurs sous Windows : l'intégration
en worgroup et l'intégration en domaine. 6.6. Configuration, paramétrage
Stockage local des options de configuration du systčme d'exploitation au sein du Registre, c'est ŕ dire une base de données sécurisée
hébergée dans un certain nombre de fichiers placés pour certains dans les répertoires du systčme d'exploitation et pour d'autres dans les
profils des utilisateurs. 6.7. Stratégie de groupe La stratégie de groupe est un vaste ensemble d'éléments de configuration du systčme d'exploitation. Ce sont ainsi probablement plusieurs dizaines de milliers de paramčtres qui peuvent ętre configurés concernant ŕ peu prčs tous les aspects du fonctionnement de la machine.
Certains de ces éléments sont relativement génériques, d'autres sont spécifiquement dédiés ŕ la gestion de la sécurité. Toutes ces options sont
stockées dans le registre sur les machines en dehors d'un domaine et dans Active Directory avec synchronisation automatique des postes clients
pour les machines faisant partie d'un domaine. Via la stratégie de groupe il est ainsi possible de gérer de façon centralisée le fonctionnement
de l'ensemble des machines d'un domaine. 6.7.1. Stratégie de sécurité
La stratégie de sécurité est un sous-ensemble de la stratégie de groupe dédié ŕ la gestion des paramčtres de configuration des aspects sécuritaires : Non sécurisés ou peu sécurisés, les premiers systčmes d'exploitation ont évolué pour intégrer des composants de gestion de la sécurité de plus en plus élaborés. 7.1.1. Unix 7.1.2. Windows 7.1.3. Recommandations générales
Autant que possible, essayer de gérer les utilisateurs par lots dans des groupes plutôt qu'individuellement.
Politique de gestion des comptes :
Politique de sécurité : 7.2. Gestion des fichiers et des répertoires 7.2.1. Linux 7.2.2. Windows 7.2.3. Recommandations générales
Privilégier la gestion en groupes ŕ la gestion ŕ l'utilisateur. 7.3. Mises ŕ jour du systčme d'exploitation 7.3.1. Linux 7.3.2. Windows 7.4. Autres aspects de la sécurité Attaques via ingénierie sociale : Attaques physiques : |